- 스칼라 벡터 행렬
- 스팬, 베이스, 랭크
- numpy로 선형 대수 연산 수행
선형 대수학을 배우는 이유
선형 대수학: 데이터 과학에서 정답에 가장 가까운 방법을 찾아 문제를 해결하는 데 사용되는 벡터와 행렬을 다루는 수학.
이 벡터는 데이터 과학의 데이터 분석에 어떻게 적용됩니까?
- 데이터 분석을 위해서는 정렬된 벡터 형태의 데이터가 필요합니다. → 먼저 데이터를 벡터화한 다음 기계 학습 모델을 만듭니다.
- 치수 축소 → 데이터는 종종 여러 차원으로 제공됩니다. 차원의 수가 증가할수록 데이터 분석이 어려워지므로 벡터를 이용한 차원축소 기법을 이용하여 고차원 데이터를 저차원 공간으로 변환할 수 있다. (PCA)
- 유사성 측정 : 벡터를 사용하면 데이터 포인트 간의 유사도를 측정할 수 있습니다. 벡터 간의 거리와 코사인 유사도를 이용하여 클러스터링, 분류, 추천 시스템 등을 사용할 수 있습니다.
- 기계 학습
- 이미지 분석 시: 이미지는 2차원 픽셀 배열로 표현되며 각 픽셀은 특징으로 간주되며 각 이미지는 벡터로 변환되어 다양한 이미지 분석 작업을 수행합니다.
→ 데이터 분석에서 분석을 위해 데이터를 벡터 형태로 변환하는 것이 중요합니다.그래서 선형대수는 필수!!
파이썬 데이터 구조
정렬된 데이터 유형(목록 대 배열)
- 리스트 : 수치연산 불가 / 데이터형 과부하 가능
- 정렬: 수치 계산 가능 / 같은 데이터 타입만 허용 /Numpy 배열(혼합 데이터 유형인 경우 모두 문자열로 처리됨)
정렬되지 않은 데이터 유형(세트)
기본 선형 대수학
– 1차원 배열: 벡터
– 2D 어레이: 매트릭스
벡터
스칼라 집합입니다. 크기와 방향으로 정의되는 값
- 목록이나 배열의 형태로 표시할 수 있습니다.
- 성분의 수 벡터의 차원 의미
- 벡터의 크기: norm, length, 크기: 벡터의 길이
- 벡터의 내적
- 유클리드 공간에서 두 벡터를 숫자처럼 곱하여 스칼라를 구하는 연산
- a b = ||a|| ||ㄴ|| cos(θ) → 두 벡터의 유사성방향을 결정할 수 있다
np.dot(v1, v2)
- 벡터의 직교(직교성) : 스칼라곱 = 0 : 서로 직교 → 상호 독립 벡터(선형독립)
- 단위 벡터(단위 벡터) : 모든 벡터는 단위 벡터의 선형 조합으로 쓸 수 있습니다.
- 선형 조합 : 내적과 벡터의 합으로 표현되는 벡터와 스칼라
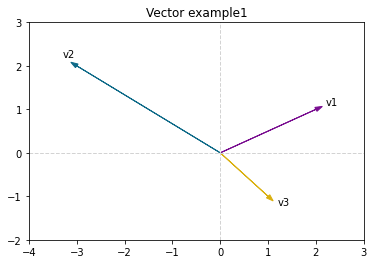
# 파이썬으로 벡터 시각화하기
v1 = (2,1)
v2 = (-3,2)
v3 = (1,-1)
plt.xticks(np.arange(-4,4))
plt.yticks(np.arange(-2,4))
# axhline : 수평선그리기 / axvline : 수직선 그리기
plt.axhline(0,0,1, color="lightgray", linestyle="--", linewidth=1)
plt.axvline(0,0,1, color="lightgray", linestyle="--", linewidth=1)
# arrow(시작x, 시작y, 가리키는x, 가리키는y) : 화살표 그리는 함수
plt.arrow(0,0,v1(0),v1(1), head_width=0.1)
plt.text(2.2, 1.1, 'v1')
# v2,v3도 똑같이.
행렬
- 행렬 곱셈:
np.matmul- 2D 공간에서 np.dot 작업과 동일합니다.
- mxl, 1xn = mxn
- 단위 행렬
np.identitynp.eye: (기본값:k=0) k에 따라 대각선 위치를 변경할 수 있습니다.
- 역행렬
np.linalg.inv
- 대각선 행렬: 주 대각선을 제외한 모든 요소가 0인 정사각형 행렬.
- 결정자(결정)
- 데트(A) = |A| = 광고 기원전
np.linalg.det- 행렬의 가역성을 결정하는 데 사용
- 역행렬 존재 O : invertible(=non-singluar matrix) det(A)≠0 선형독립
- 역행렬 존재 X : 비가역(=단일행렬) det(A)=0 선형종속
- 행렬을 형성하는 벡터는 0 벡터이거나 한 벡터가 다른 벡터에 선형적으로 의존합니다.
- 공간을 만들 수 있는 솔루션은 없습니다 ⇒ 2D 평면의 면적이 0입니다.
- 기간
- 주어진 두 벡터를 결합하여 만들 수 있습니다. 가능한 모든 선형 조합의 집합
- 예) (1,2)와 (2,4)의 범위: (x,y) = a(1,2) + b(2,4) = (a+2b, 2a + 4b )는 다음 형식으로 표현할 수 있습니다.
- 모든 벡터는 선형적으로 독립적입니다 ⇒ 스팬의 차원은 벡터의 수입니다.
- 두 벡터가 같은 선상에 있으면 선형 관계를 갖습니다.
- 선형 관계에서 벡터에 의해 생성된 스팬는 선형 숫자이므로 벡터 수보다 차원이 적습니다. (선형 종속)
- 선형적으로 관련되지 않은 벡터 = 선형적으로 독립적입니다. (선형 독립)
- 베이스
- 엘초기에 독립적인 벡터 모음
- R^2의 기저(2차원 벡터 공간): {(1,0), (0,1)}
- 마지막으로 범위의 차원은 기저 벡터의 수로 정의됩니다.
- 계급
- 벡터를 사용하여 만들 수 있는 범위의 차원
- 행렬이 나타낼 수 있는 벡터 공간의 염기 수
- 행렬에서 선형적으로 독립적인 행 또는 열의 최대 수
- 범위의 수는 순위를 통해 결정될 수 있습니다.
- 선형독립인지 종속인지 판단 가능
np.linalg.matrix_rank
예) 4개의 벡터 중 하나가 다른 벡터와 선형관계라면 스팬의 수는? 삼
- 가우스 제거를 참조하십시오.
더 공부하다
- 벡터의 크기를 지정하는 방법
- L1 규범 : ||v||₁ = |v1| + |v2| + … + |vn|
- L2 규범 : ||v||₂ = √(v₁² + v₂² + … + vn²) (유클리드 거리)
- 실수
- 모델의 예측 정확도를 측정하는 데 사용됩니다.
- 이 값이 작을수록 모델의 예측 값이 실제 값에 더 가깝습니다.
- MSE (평균 제곱 오차)
- 실제 값과 예측 값의 차이 제곱을 합한 다음 샘플 수로 나눈 값
- 예측오차는 제곱이므로 예측오차가 큰 값일수록 민감함 → 오차에 더 많은 가중치 부여
- 마에 (중간절대오차)
- 실제 값과 예측 값의 차이 절대 값을 합한 다음 샘플 수로 나눈 값
- 마찬가지로 예측오차는 제곱하지 않기 때문에 예측오차의 크기에 가중치를 부여하여 예측오차의 크기에 대한 보다 효과적인 솔루션을 제공합니다.
예측 오차에 대한 가중치 → MSE는 큰 예측 오류에 대해 더 강력한 페널티 줌을 제공하며 MAE 크기에 관계없이 동일한 페널티 줌을 제공합니다.
np.stack
여러 배열을 하나의 배열로 병합하는 기능
a = np.array((1,2,3))
b = np.array((2,3,4))
np.stack((a,b))
>>array(((1, 2, 3),
(2, 3, 4)))
np.stack((a,b), axis=1)
>> array(((1, 2),
(2, 3),
(3, 4)))
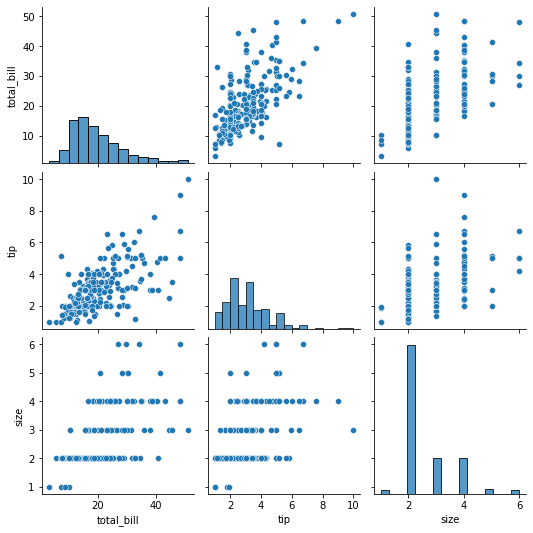
%%timeit: 코드 실행 시간 측정에 편리합니다.10000 loops, best of 5: 13.2 µs per loop # 코드 10000번 반복해서 실행 시, 5번 실행 결과 중 가장 작은 실행 시간 선택 # '13.2' : 평균 실행 시간`sns.pairplot- 한 번에 모든 열 사이에 산점도를 그리는 기능
tips = sns.load_dataset('tips') # total_bill, tip, size 열간의 산점도 그리기기 sns.pairplot(tips, vars=("total_bill", "tip", "size")) # 대각선 부분은 histogram으로 나타남. diag_kind파라미터를 통해 변경 가능
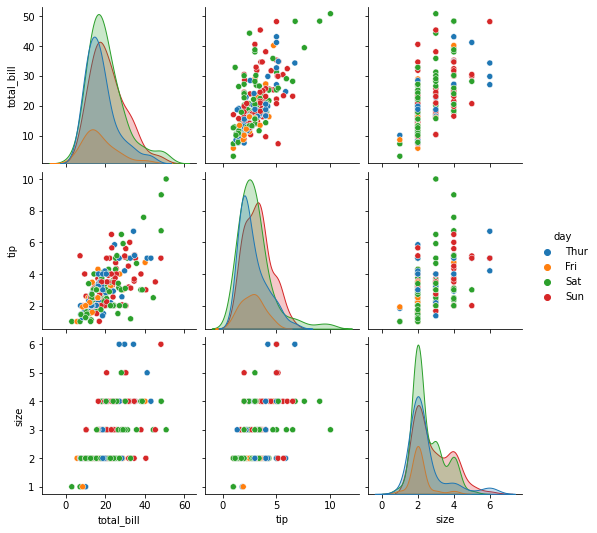
# 'day' 열에 따라 색상을 다르게 해서 산점도 그리기
sns.pairplot(tips, vars=("total_bill", "tip", "size"), hue="day", diag_kind='kde')
# diag_kind가 KDE로 대각선부분에 확률밀도함수를 그려줌.
# 회귀선 추가하기
sns.pairplot(tips, x_vars=("total_bill"), y_vars=("tip"), kind="reg")
- 크래머의 법칙
- 선형 방정식을 푸는 방법 중 하나
- 각 변수의 계수를 행렬로 표현하여 행렬식을 이용하여 해를 구하는 방법
ax + by = e cx + dy = f # 해를 구하는 공식 x = (ed - bf) / (ad - bc) y = (af - ec) / (ad - bc) # 이떄, 행렬식(det)을 이용하여 ad-bc 계산# 크래머의 규칙 : 선형 방정식의 해를 구하는 방법 중 하나 # 각 변수의 계수를 행렬로 나타내어, 행렬식을 이용하여 해를 구하는 방법 A = np.array(((1, 0, 2), (-3, 4, 6), (-1, -2, 3))) B = np.array((6, 30, 8)) # det먼저 구해주기 det = np.linalg.det(A) # 원래 행렬의 각 열의 값 변경 -> x1은 첫번째 열 B로 대체 x1 = np.linalg.det((( 6, 0, 2), (30, 4, 6), ( 8, -2, 3))) / det # x2는 두번째 열 B로 대체 x2 = np.linalg.det((( 1, 6, 2), `` (-3, 30, 6), (-1, 8, 3))) / det # x3은 세번째 열 B로 대체 x3 = np.linalg.det((( 1, 0, 6), (-3, 4, 30), (-1, -2, 8))) / det - 선형 투영
- proj_b(a) = (ab / ||b||^2) * b : 벡터 a를 벡터 b에 수직 투영한 결과
- 먼저 내적의 원리를 살펴보자.
- w 대 v를 투영해 봅시다. V·w = (투영된 w의 길이) x (v의 길이)
- w-벡터 발사체가 v-벡터의 반대 방향에 있으면 내적은 음수입니다.
- 물론 같은 방향으로 가면 내적은 양수입니다.
- 그리고 직각을 이루는 경우 투영은 0이 되고 내적은 0이 된다.
- v를 투영한 결과와 w를 투영한 결과는 같으므로 순서는 중요하지 않다는 것을 알 수 있습니다.
- 데이터를 나타내기 위해 두 개의 특성 x와 y가 필요함 → 투영 → 데이터를 나타내기 위해 하나의 특성 x만 필요함
- 다음에 배울 PCA에서는 선형 투영의 개념이 중요합니다.
- 내적(dot product)과 투영(projection)이 어떻게 연관되어 있는지 알아봅시다.
- 코사인 유사도
- 내적과 투영을 사용하여 계산되는 두 벡터의 유사성을 측정하는 지수입니다.
- cosine_similarity(a, b) = ab / (||a|| ||b||) = proj_b(a) / ||a||
- 두 벡터의 방향이 유사할수록 코사인 유사도는 1에 가까워집니다.
- 방향이 반대이면 -1
- 코사인 유사도